What is Max_features in random forest?

Matthew Alvarez
Published May 30, 2026
.
Hereof, what is N_estimators in random forest?
n_estimators : This is the number of trees you want to build before taking the maximum voting or averages of predictions. Higher number of trees give you better performance but makes your code slower.
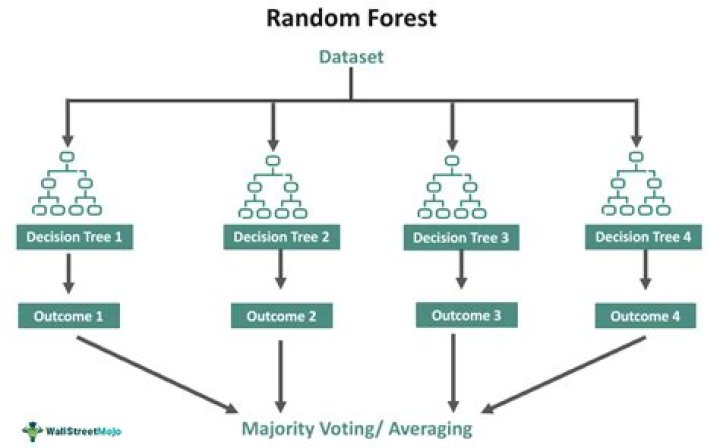
what does a random forest do? Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual
Beside this, what are Hyperparameters in random forest?
In the case of a random forest, hyperparameters include the number of decision trees in the forest and the number of features considered by each tree when splitting a node. (The parameters of a random forest are the variables and thresholds used to split each node learned during training).
What causes random forest to Overfit the data?
The hyper parameter when increased may cause random forest to over fit the data is the Depth of a tree. Over fitting occurs only when the depth of the tree is increased. Under fitting can also be caused due to increase in the number of trees.
Related Question AnswersDoes Random Forest Overfit?
Random Forests does not overfit. The testing performance of Random Forests does not decrease (due to overfitting) as the number of trees increases. Hence after certain number of trees the performance tend to stay in a certain value.How do you increase the accuracy of a random forest?
Now we'll check out the proven way to improve the accuracy of a model:- Add more data. Having more data is always a good idea.
- Treat missing and Outlier values.
- Feature Engineering.
- Feature Selection.
- Multiple algorithms.
- Algorithm Tuning.
- Ensemble methods.
How do I stop Overfitting random forest?
1 Answer- n_estimators: The more trees, the less likely the algorithm is to overfit.
- max_features: You should try reducing this number.
- max_depth: This parameter will reduce the complexity of the learned models, lowering over fitting risk.
- min_samples_leaf: Try setting these values greater than one.